How to optimize ORDER BY RANDOM()
Tom Witowsky (@devgummibeer) shared on Twitter a scaling issue with his service opendor.me, which helps any developer share and highlight their open source work. As the service grows, more and more data is stored in the database and needs to be browsed. One particularly slow query that he needed help optimizing is fetching random users, organizations, and repositories that are already part of the service.
The following query illustrates the problem reduced to its important component:
SELECT *
FROM repositories
ORDER BY RANDOM()
LIMIT 3
The Problem
Before we look at how the query can be optimized, we need to understand how the database processes such a query. Databases are excellent at optimizing most queries you ask them to perform, but they have their limits. However, selecting some random rows is an SQL antipattern as databases don’t have optimizations for this use case. Ordering records in a random order involves these operations:
- Load all rows into memory matching your conditions
- Assign a random value RANDOM() to each row in the database
- Sort all the rows according to this random value
- Retain only the desired number of records from all sorted records
This is a trivial task for the database if you only have a few records, but the more records you have, the less efficient this approach will be. Loading all records into memory can still be done efficiently with slightly larger tables, but sorting all of them will become significantly slower as the size of the database increases. Any database has a limit on the size of data that can be sorted in memory to ensure the stability of the database server. MySQL controls the maximum amount of data that can be sorted in memory via the sort_buffer_size setting, while PostgreSQL uses the work_mem variable. On both systems, these values are typically less than 10MB. Because of this, to sort a large data set the database creates a temporary file to sort small chunks one at a time and merge them together later. Depending on the size many read and write operations are required.
Trying different Approaches
Random Offset
A simple solution is to use a column with sequential numbers. This column can be an existing primary key or a new column added for this purpose. The query uses a random number in the range of the column’s values:
SELECT *
FROM repositories
WHERE id IN(
SELECT floor(random() * (COUNT(*)) + 1) FROM repositories
UNION
SELECT floor(random() * (COUNT(*)) + 1) FROM repositories
UNION
SELECT floor(random() * (COUNT(*)) + 1) FROM repositories
)
The approach is simple, but also has many problems:
- Deleting records produces gaps in the continous range which must be refilled.
- You cannot use conditions in the query or else there will be gaps.
- Records can appear more than once in the result set.
Random Range
The idea of using a randomized offset can be further improved. Instead of specifying a particular row and forcing the dataset to have no gaps, the random value is used to indicate the starting point of a range search:
SELECT *
FROM repositories
WHERE id <= (SELECT floor(random() * (COUNT(*)) + 1) FROM repositories)
LIMIT 3
The approach solves both previous problems but has new problems:
- The gaps created by deletions cause an imbalance.Deleting some consecutive records will lead to a higher probability of the next record
- Excluding some rows by conditions causes gaps that also cause an imbalance
- Some random values will result in a smaller number of records than intended (e.g. a very low random value)
The Solution
Description
The last approach is the best one so far. Selecting random records based on a range search satisfiable by an index is promising. Based on the last approaches, a solution needs to have the following properties:
- Gaps must not lead to imbalances
- A selected random starting point must be able to lead to the desired number of results, independent of the value
There is a functionality in databases that fulfills all these conditions. One can use the spatial extensions to assign a random value to each row in a two-dimensional space, thus creating a perfectly random distribution for a large number of records. With only a few records the distribution is not as perfect:
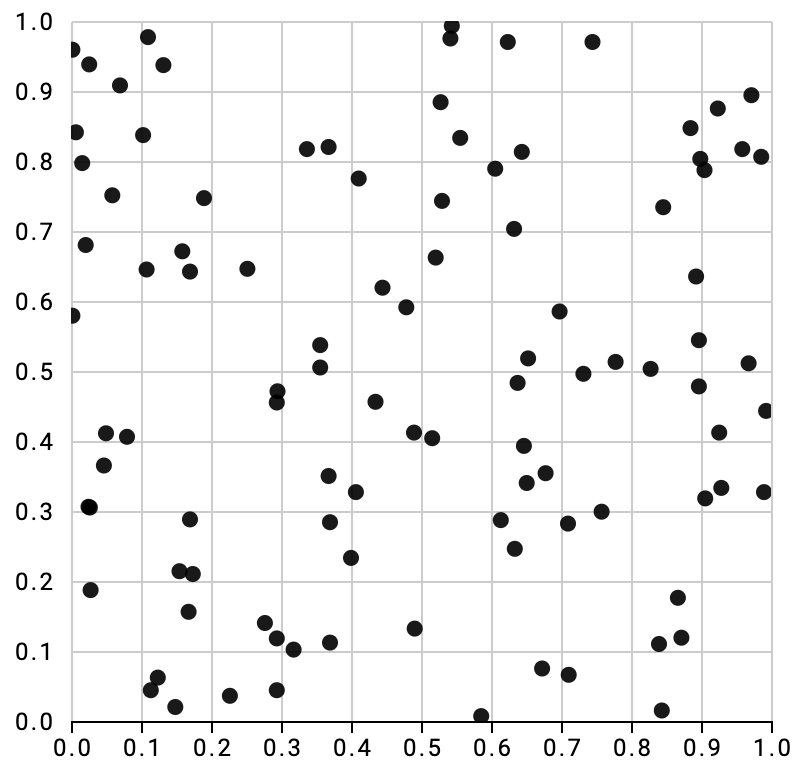
Implementation
The following solution is built for PostgreSQL, but can be easily applied to any other database. To use the spatial functionality, we add a column to the table with a spatial data type for a point in two-dimensional space and update all previous values with a random value. To make the implementation efficient, we also create an index for this column.
ALTER TABLE repositories ADD COLUMN randomness point;
UPDATE opendor SET randomness = point(random(), random());
CREATE INDEX repositories_randomness on repositories using spgist(randomness);
With the database now distributing all records uniformly in a two-dimensional space, the data can be queried. The query to find random values is now performed using the k-nearest neighbors (k-NN) algorithm indicated by the <-> operator with reference to a random point in the created two-dimensional space. Though the following query does not include any further conditions to narrow the result set, it is possible to do so and will not change the random distribution like in the failed former approaches.
SELECT *
FROM repositories
ORDER BY randomness <-> point(0.753,0.294)
LIMIT 3;
Final Remarks
This method is still fast with several million records and consistently takes less than 1 millisecond to execute. Database optimizations are very difficult sometimes, but there are solutions for event the most complex problems, you just have to get creative.